Webサイト作成では、大量のhtmlタグを扱います。検索や置換の際、正規表現パターンが使えると作業がより軽減できます。しかし、正規表現のメタタグの構文を読むだけでは、さっぱり理解できないと思います。
ただ、正規表現パターンは、なれないうちは、希望通りの挙動を示す正規表現パターンを作成することができません。そこで、このページでは、Webサイト作成に役立つ正規表現パターンを紹介します。
正規表現パターンの動作確認には、テキストエディタの検索置換機能を利用すると便利です。秀丸エディタで検証しました。
しかし、正規表現パターンは、それぞれのアプリケーションで微妙に、表現が異なるので注意が必要です。
HTMLタグにマッチさせる
自然文を的確に一致させる正規表現パターンを考えるのは、大変ですが、もともとコンピュータに認識させやすく設計されているHTMLタグに対して正規表現パターンを考えるのは、多少簡単なはずです。よく使用するパターンも限られているので、動作を検証しつつ、有用なパターンを一覧にしておけば、マクロを作成する際の参考にもなります。
HTMLタグに対して正規表現パターンを考えるのは、正規表現初心者が、正規表現を理解するために挑戦する題材にぴったりです。
検証に使用するhtmlファイルは、LibreOfficeで出力したhtmlファイルを使いました。
タグにマッチする正規表現パターン
htmlタグの開始は「<」、終了は、「>」です。
「<」で始まり、何か色々の文字が存在「.*」し、「>」で終了します。
<.*>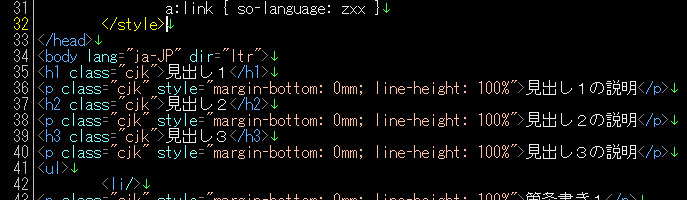
パターンマッチさせる元のテキストです。
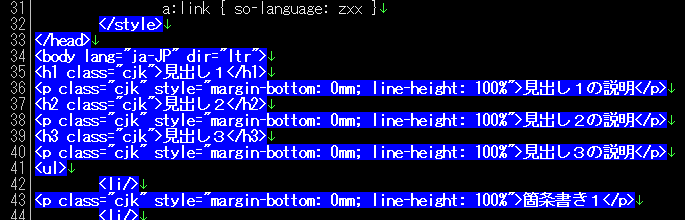
このパターンの場合、タグだけでなく、タグに囲まれた文字列にもマッチします。
タグだけにマッチさせたい場合、最短一致の量指定子を使用する方法があります。
<.*?><.+?>他の方法として、任意の文字ではなく、「>」以外の文字を指定する方法があります。
「.*」が表す任意の文字を使用することで、「>」を飛び越えて、次の「>」まで指定しまうことになりました。そこで、「>」ではないことを表す「[^>]*」とすると終了タグを表す「>」の直前までマッチします。
<[^>]*>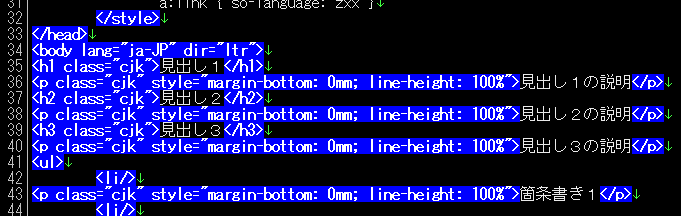
結果は全て、同じです。
特定のタグ全体にマッチさせる
次に、特定のタグについて考えてみましょう。
使用しているサンプルテキストのタイトルタグは、空欄です。「ページタイトル」を追加します。
<title>ページタイトル</title>では、このタイトルタグにマッチする正規表現パターンを考えてみましょう。
タグも含めてマッチさせる場合、以下のようになります。
<title>(.*?)</title>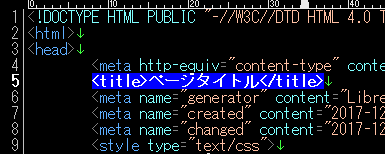
タイトルタグとその内容が選択されます。
タグを選択する例と同じく、「.*?」の代わりに、「.+」、「.*」、「.+?」が使えます。タイトルタグは、ページに1つしか存在しないので、「.+」、「.*」でも問題はおきませんが、他のタブでは、問題が起きるので、「.*?」、「.+?」を使用しましょう。
他のタグについても同じように考えることができます。
コメントタグにマッチさせる場合
<!--.+?-->aタグにマッチさせる場合
<a .+?/a> 特定のタグの内容マッチさせる
タイトルタグの内容、つまり、開始タグと終了タグの間のテキストにだけ、マッチさせる場合は、以下のようになります。
(?\1)<title>(.*?)</title>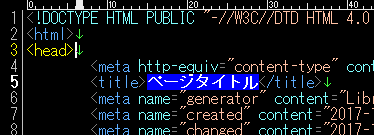
タイトルの内容だけが選択されます。
文頭の「(?\1)」は、(?\tag-number)メタタグを示しています。 (?\tag-number)を使うことで、検索でマッチした扱いにする部分を、検索パターン中のタグの指定で行うことが出来ます。 (?\tag-number)は、正規表現のDLLにHmJre.dllを指定している場合に有効なメタキャラクタであることに注意して下さい。
属性にマッチさせる
属性にマッチさせるには、以下の正規表現パターンを使用します。
style="(.*?)"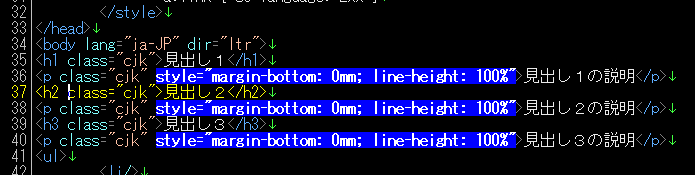
スタイル属性が選択されました。この正規表現パターンを使用すれば、Microsoft WordやLibreOffice Writerの文書をhtml形式で出力する際、無駄についてくるスタイル属性を一度に削除することも簡単です。
属性の内容にマッチさせる
内容にマッチさせる場合は、「(?\1)」を正規表現パターンの先頭に追加します。
(?\1)name="(.*)"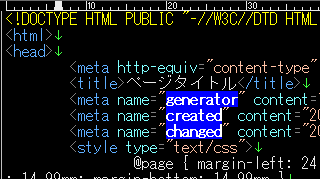
name属性の内容だけが選択できました。
特定のタグの属性の内容にマッチさせる
特定のタグの属性の内容にマッチさせるには、以下の正規表現パターンを使用します。
(?\2)<table(.*?)width="(.*?)"(.*?)>「(?\2)」の数字は、この正規表現パターンの中で使用されている「()」の2つ目の内容を取り出すことを示しています。
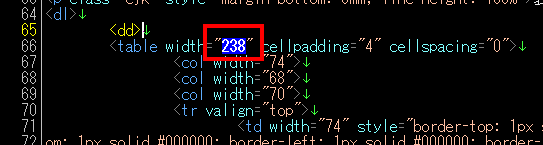
tableタグのwidth属性の内容だけが選択されています。colタグやtdタグのwidth属性の内容は選択されていません。
複数行に渡ってマッチさせる
複数行に渡ってマッチさせるには、どのように指定したら良いのでしょうか?
複数行に渡るスタイル属性にマッチしたいと考えます。
以下は、対象とするテキストの一部の抜粋です。
<head>
<meta http-equiv="content-type" content="text/html; charset=utf-8"/>
<title>ページタイトル</title>
<meta name="generator" content="LibreOffice 5.4.3.2 (Windows)"/>
<meta name="created" content="2017-12-21T16:32:21.702000000"/>
<meta name="changed" content="2017-12-21T18:00:03.338000000"/>
<style type="text/css">
@page { margin-left: 24.99mm; margin-right: 14.99mm; margin-top: 14.99mm; margin-bottom: 14.99mm }
p { margin-bottom: 2.47mm; direction: inherit; line-height: 120% }
p.cjk { font-size: 10pt }
h1 { margin-bottom: 2.12mm; direction: inherit }
h1.western { font-family: "Liberation Sans", sans-serif; font-size: 18pt }
h1.cjk { font-family: "HGゴシックE", monospace; font-size: 21pt }
h1.ctl { font-family: "Arial Unicode MS"; font-size: 18pt }
h2 { direction: inherit }
h2.western { font-family: "Liberation Sans", sans-serif; font-size: 16pt }
h2.cjk { font-family: "HGゴシックE", monospace; font-size: 18pt }
h2.ctl { font-family: "Arial Unicode MS"; font-size: 16pt }
h3 { direction: inherit }
h3.western { font-family: "Liberation Sans", sans-serif; font-size: 14pt }
h3.cjk { font-family: "HGゴシックE", monospace; font-size: 16pt }
h3.ctl { font-family: "Arial Unicode MS"; font-size: 14pt }
td p { margin-bottom: 0mm; direction: inherit }
td p.cjk { font-size: 10pt }
a:link { so-language: zxx }
</style>
</head>「.」(ピリオド)は、改行を除く任意の1文字 にマッチするため、複数行に渡ってマッチさせる場合には使用できません。
この場合、空白を示す「\s」([ \t\r\n]と同じ) と空白以外を示す「\S」を使用します。つまり、「.*?」の代わりに、「[\s\S]*?」を使用すれば、いいような気がしますが、うまく動作しません。
<style([\s\S]*)</style>\nを使った複数行検索の際の制限について(Ver8.71対応版)
秀丸エディタでは、複数行に渡ってマッチさせるのは、難しいと考えていいようです。
このような、複数行にまたがる一致は、正規表現ではなく、マクロで対処することになります。
汎用テキストエディタの秀丸エディタを使って、LibreOfficeで作成したhtmlファイルの<head>タグを削除する
最新版の状況は確認していませんが、サクラエディタでも、正規表現パターンを使用した複数行のマッチは、問題になっているようです。
他の汎用エディタの対応が気になります。MIFES(マイフェス) の機能紹介ページでも特別な記述はありません。使えないとは思えませんが、「複数行に渡ってマッチさせる」機能は、テキストエディタ購入前に、サポートに問い合わせて確認したほうが良いと思います。
参考:MIFES(マイフェス)